| 4. FEJEZET | Tartalom | 6. FEJEZET |
5. FEJEZET:
Mutatók és tömbök
A mutató vagy pointer olyan változó, amely egy másik változó címét tartalmazza. A C nyelvű programokban gyakran használják a mutatókat, egyrészt mert bizonyos feladatokat csak velük lehet megoldani, másrészt mert alkalmazásukkal sokkal tömörebb és hatékonyabb program hozható létre. A mutatók és a tömbök szoros kapcsolatban vannak egymással és ebben a fejezetben ezt a kapcsolatot vizsgáljuk, ill. megmutatjuk, hogy ez a kapcsolat hogyan használható ki.Gyakran a mutatót összekapcsolják a goto utasítással, mondván, hogy mindkettő csodálatos lehetőséget teremt az érthetetlen programok írásához. Ez biztosan így is van, ha nem kellő gondossággal használjuk, hiszen könnyű olyan mutatót létrehozni, amely valamilyen nem várt helyre mutat. Kellő fegyelemmel viszont elérhető, hogy a mutatókat használó program világos és áttekinthető legyen. A következőkben ezt próbáljuk meg bemutatni.
Az ANSI C egyik legfontosabb új eleme, hogy explicit szabályokat tartalmaz a mutatók használatára, amelyeket a jó programozók a gyakorlatban kihasználnak és a jó fordítóprogramok érvényre juttatnak. A korábbi C változathoz képest változás még, hogy a char * általános mutató helyett bevezették a void * mutatótípust.
5.1. Mutatók és címek
A vizsgálatainkat kezdjük a számítógép tárolójának szervezését leíró egyszerű képpel! A tipikus számítógép tárolója egymást követő, folyamatosan számozott vagy címezett tárhelyekből áll, amelyekkel egyenként vagy folytonos csoportokban végezhetünk műveleteket. Elég gyakori, hogy a tároló bármelyik bájtja egy karakter, bájt-párja egy short típusú egész szám és négy szomszédos bájtja egy long típusú egész szám tárolására alkalmas. Egy mutató a tárolóelemek egy csoportja (gyakran két vagy négy bájt), amely egy címet tartalmazhat. Ezért, ha c egy char típusú változó és p egy rá mutató (azt címző) mutató, akkor a helyzet a következő vázlatnak megfelelően alakul.

Az & unáris (egyoperandusú) operátor megadja egy operandus címét, ezért a
p = &c;
utasítás c címét hozzárendeli a p változóhoz és ilyenkor azt mondjuk, hogy p c-re „mutat”. Az & operátor csak változókra és tömbelemekre alkalmazható és nem használhatjuk kifejezésekre, állandókra, vagy regiszterváltozókra.A * unáris operátor neve indirekció, és ha egy mutatóra alkalmazzuk, akkor a mutató által megcímzett változóhoz férhetünk hozzá. Tegyük fel, hogy x és y egésztípusúak és ip egy int típushoz tartozó mutató. A következő, elég mesterkélt példán bemutatjuk a mutatók deklarálását, valamint az & és * operátorok használatát.
int x = 1, y = 2, z[10]; int *ip; ip = &x; y = *ip; *ip = 0; ip = &z[0];
x, y és z deklarációja az eddig látott módon történik, az ip mutatót
int *ip; módon deklaráljuk, és azt mondjuk *ip egy int. A változók deklarációjának szintaxisa annak a kifejezésnek a szintaxisát követi, amelyben a változót használjuk. Ezt a meggondolást már eddig is alkalmaztuk a függvények deklarációjánál. Ennek mintájára pl.
double *dp, atof(char *);
azt jelenti, hogy egy kifejezésben *dp (a dp mutatóval kijelölt változó értéke) és atof értéke double típusú, ill. az atof argumentuma char típushoz tartozó mutató.Az indirekció alapján látható, hogy egy mutató mindig meghatározott objektumra mutat, azaz minden mutató meghatározott adattípust jelöl ki. (Ez alól csak egy kivétel van, a void típushoz tartozó mutató, ami egy olyan adat, amely bármilyen mutatót tartalmazhat. Erre az a megszorítás érvényes, hogy önmagára nem alkalmazhatja az indirekciót. A kérdésre az 5.11. pontban még visszatérünk.)
Ha ip egy x egészre mutat, akkor *ip minden olyan programkörnyezetben előfordulhat, ahol x használata megengedett. Így pl. megengedett a
*ip = *ip + 10;
értékadás is, amely *ip-et tízzel növeli.Az & és * unáris operátorok szorosabban kötnek, mint az aritmetikai operátorok, ezért az
y = *ip + 1
kifejezés kiértékelésekor a gép először veszi azt az adatot, amire ip mutat, hozzáad egyet, majd az eredményt hozzárendeli y-hoz. Az
*ip += 1
inkrementálja azt a változót, amire ip mutat, csakúgy, mint a
++*ip
vagy az
(*ip)++
Az utolsó esetben a zárójelre szükség van, mert hiányában az ip inkrementálódna az ip által kijelölt adat helyett, mivel a *-hoz és ++-hoz hasonló unáris operátorok jobbról balra hajtódnak végre.Mivel a mutatók is változók, ezért indirekció nélkül is használhatók kifejezésekben. Ha pl. iq egy int adatot címző mutató, akkor
iq = ip
értékadás hatására ip tartalma iq-ba másolódik, függetlenül attól, hogy ip mire mutat.
5.2. Mutatók és függvényargumentumok
Mivel a C nyelv a függvényeknek érték szerint adja át az argumentumokat, így a hívott függvény nem tudja megváltoztatni a hívó függvény változóit. Például a rendező programban használtuk a swap függvényt a rossz sorrendben lévő adatok felcserélésére. Itt nem elegendő, ha azt írjuk, hogy
swap(a, b);
ahol a swap függvényt úgy definiálnánk, hogy
void swap(int x, int y) { int temp; temp = x; x = y; y = temp; }
Mivel a függvényt érték szerint hívjuk, a swap nem képes a hívásában szereplő a és b argumentumokat befolyásolni (azoknak csak egy helyi másolatával dolgozik, ezek cseréje pedig nem befolyásolná az eredeti argumentumok sorrendjét).A kívánt hatás csak úgy érhető el, ha a hívó függvény mutatókat ad át a hívott függvénynek.
swap(&a, &b);
Mivel az & operátor a változó címét állítja elő, ezért az &a az a-hoz tartozó mutató. Ha a swap függvényben a paramétereket mutatóként deklaráljuk, akkor indirekt módon hozzáfér az operandusokhoz és így közvetlenül felcserélheti azokat. Az így megírt swap függvény:
void swap(int *px, int *py) { int temp; temp=*px; *px = *py; *py = temp; }
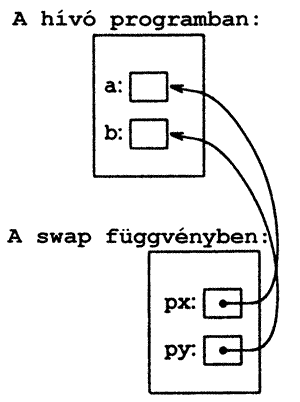
A folyamatot egyszerű ábrával is szemléltethetjük. Egy függvény a mutató típusú argumentumokon keresztül képes hozzáférni és megváltoztatni a hívó eljárás objektumait. Példaként írjuk meg a getint függvényt, amely egy szabad formátumú bemeneti konvertáló eljárás. A getint a bemeneti karakteráramból hívásonként egy egész típusú értéket emel ki és visszaadja azt a hívó függvénynek, ill. jelzi a bemeneti állomány végét. A kapott egész számot és az EOF jelzését két külön csatornán kell megoldani, mivel az EOF jelzése maga is egy egész szám lehet, ami a beolvasott értékkel keveredve zavart okozhatna.Azt a megoldást választottuk, hogy az EOF-ra utaló állapotjelzést a függvény visszatérési értékével adjuk át a hívó programnak, a beolvasott egész számot pedig mutató típusú argumentumon keresztül. (A 7.4. pontban ismertetésre kerülő scanf függvény ugyanilyen módon működik.) Az
int n, tomb[MERET], getint(int *); for (n = 0; n < MERET && getint(&tomb[n]) != EOF; n++) ;
ciklus getint hívásokkal feltölti a tömböt. A getint minden hívásakor a beolvasott egész számot elhelyezi a tomb[n] pozícióra, majd a hívó ciklus inkrementálja n értékét. A helyes működéshez a híváskor a tomb[n] tömbelem címét kell a getint függvénynek átadni, mert az csak ennek felhasználásával tudja a talált számot visszaadni a hívó eljárásnak.A getint függvény itt közölt változatának visszatérési függvényértéke EOF, ha elérte az állomány végét, nulla, ha a következő bemeneti adat nem szám és pozitív érték, ha az eredmény érvényes egész szám (ami a tomb[n] helyen van). A program:
#include <ctype.h> int getch(void); void ungetch(int); int getint(int *pn){ int c, sign; while(isspace(c = getch())) ; if(!isdigit(c) && c != EOF && c != '+' && c!= '-') { ungetch (c); return 0; } sign = (c == '-') ? -1 : 1; if(c == '+' || c == '-') c = getch(); for(*pn = 0; isdigit(c); c = getch()) *pn = 10 * *pn + (c - '0'); *pn *= sign; if(c != EOF) ungetch(c); return c; }
A *pn-t a teljes getint függvényben úgy használjuk, mint egy közönséges int típusú változót. A getint szintén használja a 4.3. pontban leírt getch és ungetch függvényeket, mivel a feleslegesen beolvasott karaktert most is vissza kell írni a bemenetre.
5.1. gyakorlat. Ahogy ezt a példaprogramban láttuk, a getint az olyan + vagy – előjelet, ami után nem következik számjegy, érvényes, nulla értékű adatként kezeli. Szüntessük meg ezt a problémát úgy, hogy egy nullát visszaírunk a bemenetre!
5.2. gyakorlat. Írjuk meg a getfloat függvényt, ami a getint lebegőpontos megfelelője! Milyen típusú függvényértékekkel tér vissza a getfloat?
5.3. Mutatók és tömbök
A C nyelvben a mutatók és a tömbök között szoros kapcsolat van, ami indokolja, hogy a két dolgot közösen tárgyaljuk. Bármilyen művelet, amit egy tömb indexelésével elvégezhetünk, megoldható mutatókkal is. A mutatót használó programváltozat általában gyorsabb, de legalábbis a kezdők számára nehezebben érthető. Az
int a[10]; deklaráció egy tízelemű tömböt jelöl ki, azaz tíz egymást követő, a[0]…a[9] névvel ellátott objektumot.

Az a[i] jelölés a tömb i-edik elemére hivatkozik. Ha pa egy egész típushoz tartozó mutató, amit
int *pa; módon deklaráltunk, akkor a
pa = &a[0];
értékadás hatására pa az a tömb nulladik elemére fog mutatni, vagyis pa az a[0] címét fogja tartalmazni.
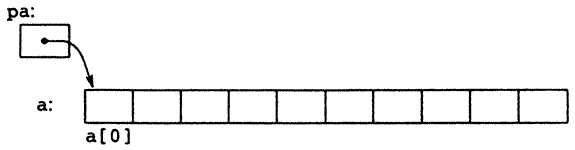
Most nézzük az
x=*pa;
értékadást! Ez az a[0] tartalmát fogja az x-be másolni.Ha pa egy tömb adott elemére mutat, akkor definíció szerint pa+1 a következő elemre, pa+i a pa utáni i-edik elemre és pa-i a pa előtti i-edik elemre fog mutatni. Így ha pa az a[0] elemre mutat, akkor
*(pa + 1)
a tömb a[1] elemének tartalmára hivatkozik, és pa+i az a[i] címét adja, így *(pa+i) az a[i] tartalmát jelenti.
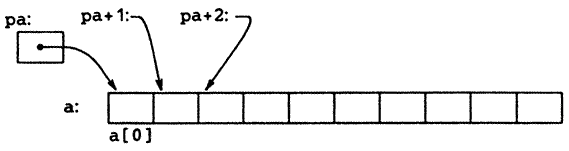
Ezek a megállapítások a tömböt alkotó változók típusától vagy méretétől függetlenül igazak. Az a kijelentés, hogy „adj 1-et a mutatóhoz” azt jelenti, hogy pa+1 a következő objektumra, hasonlóan pa+i pedig a pa utáni i-edik objektumra mutat. A teljes mutatóaritmetikára igaz, hogy a növekmény mértékegysége annak az objektumnak a térbeli mérete, amire a mutató mutat.Az indexelés és a mutatóaritmetikai műveletek közötti összefüggés nagyon szoros. Definíció szerint a tömbre való hivatkozás a tömb első (nulladik indexű) elemét kijelölő mutató létrehozását jelenti. Vagyis a
pa = &a[0];
értékadás hatására pa és a (mint a tömbre való hivatkozás) azonos értékű lesz. Mivel a tömb neve és a nulladik indexű elemének címe szinonimák, ezért a pa=&a[0] értékadás úgy is írható, hogy
pa = a;
A fenti megállapítás első látásra nagyon meglepő és azt jelenti, hogy az a[i]-re való hivatkozás *(a+i) formában is írható. Az a[i] hivatkozás kiértékelésekor a C fordító azonnal átalakítja a hivatkozást *(a+i) alakra, és a két alak egymással teljesen egyenértékű. A fenti egyenlőség mindkét oldalára alkalmazva az & operátort az következik, hogy &a[i] és a+i szintén azonosak, vagyis a+i az a utáni i-edik elem címe. Más oldalról nézve viszont ha pa egy mutató, akkor az a kifejezésekben indexelhető, vagyis pa[i] megfelel a *(pa+i)-nek. Röviden összefoglalva: bármely tömböt és indexet tartalmazó kifejezés egyenértékű egy mutatót és egy eltolást (ofszetet) tartalmazó kifejezéssel. A kétféle írásmód egyetlen utasításon belül is megengedett.A tömb neve és a mutató között csak egyetlen különbség van, amiről nem szabad elfelejtkeznünk: a mutató egy változó, tehát pa = a vagy pa++ érvényes kifejezések, a tömb neve viszont nem változó, ezért az a = pa vagy a++ alakú konstrukciók nem megengedettek!
Amikor egy tömb nevét átadjuk egy függvénynek, akkor valójában a tömb kezdetének címét adjuk át. A hívott függvényben ez az argumentum egy helyi változó lesz, így egy paraméterként megadott tömbnév lényegében egy mutató, vagyis egy címet tartalmazó változó. Ezt a tényt kihasználva írjuk meg egy tetszőleges karaktersorozat hosszát meghatározó strlen függvény egy másik változatát.
int strlen(char *s) { int n; for (n = 0; *s != '\0'; s++) n++; return n; }
Mivel s egy mutató, az inkrementálása megengedett, de az s++ nincs semmilyen hatással sem az strlen függvényt hívó függvényben a karaktersorozatra, mivel csak a mutató helyi másolata inkrementálódik. Ez azt jelenti, hogy az strlen függvényt a
strlen("Halló mindenki!"); strlen(tomb); strlen(ptr); formában és argumentumokkal híva jól működik.Egy függvény definíciójában a formális paraméterek között szereplő
char s[ ]; char *s;
megadási formák egyenértékűek, de a továbbiakban a másodikat részesítjük előnyben, mert sokkal egyértelműbben mutatja, hogy a paraméter egy mutató. Amikor egy tömb nevét adjuk át a függvénynek, a függvény szabadon dönthet, hogy tömbként vagy mutatóként kezeli (akár mindkét értelmezést is használhatja, ha az célszerű és világos).Arra is van lehetőség, hogy a tömbnek csak egy részét adjuk át a függvény hívásakor, ha a résztömb kezdetének mutatóját adjuk át. Például, ha a egy tömb, akkor
f(&a[2])
vagy
f(a+2)
átadja az f függvénynek azt a résztömböt, amely az a[2] elemmel kezdődik. Az f függvényen belül a paraméterdeklaráció
f(int rtomb[]) {...} vagy
f(int *rtomb) {...} alakú lehet. Ami az f függvényt illeti, arra semmiféle következménnyel nem jár, hogy a paraméter egy nagyobb tömb része.Ha biztosak vagyunk benne, hogy a megfelelő tömbelem létezik, akkor megengedett a tömb visszafele indexelése is. A p[-1], p[-2] stb. szintaktikailag helyes és a tömb p[0] elemét közvetlenül megelőző elemekre való hivatkozást jelent. Természetesen nem hivatkozhatunk olyan objektumra, ami nincs a tömb határain belül.
5.4. A címaritmetika
Ha p egy tömb valamelyik elemének mutatója, akkor p++ inkrementálja a p mutatót, hogy az a tömb következő elemére mutasson és p+=i pedig úgy növeli p-t, hogy az az aktuális elem utáni i-edik elemre mutasson. Ezek, ill. az ehhez hasonló konstrukciók a mutató- vagy címaritmetika legegyszerűbb esetei.A C nyelv következetesen és szisztematikusan közelít a címaritmetikához: a mutatók, tömbök és a címaritmetika egységes kezelése a nyelv egyik pozitívuma. Ennek szemléltetésére írjunk egy primitív tárolóhely-kiosztó eljárást. Az eljárás két függvényből fog állni. Az első, alloc(n) függvény az n darab egymást követő karakterpozícióhoz tartozó mutatóval tér vissza, és ezt az alloc függvény hívója a karakterek eltárolásához fogja felhasználni. A második, afree(p) függvény felszabadítja a tárterületet, ami így később újra felhasználható lesz. Az eljárást azért neveztük primitívnek, mert az afree hívásai az alloc hívásaival ellentétes sorrendben kell hogy történjenek. Így az alloc és az afree által kezelt tárterület lényegében egy veremtár, vagyis egy „utolsó be, első ki” típusú lista. A standard könyvtár hasonló feladatot ellátó malloc és free függvényeire nincs ilyen megszorítás (ezekről részletesebben majd a 8.7. pontban olvashatunk).
A legegyszerűbb megoldás, ha az alloc egy nagy karakteres tömb, az allocbuf részeit szolgáltatja. Ez a tömb az alloc és afree függvényekre nézve saját és közös. Mivel a függvények a feladatot mutatókkal és nem indexekkel oldják meg, ezért egyetlen más eljárásnak sem kell ismerni a tömb nevét, amit az alloc és afree függvényeket tartalmazó forrásállományban static tárolási osztályúnak deklaráltunk (ezért más függvényekből nem látható). A gyakorlati megvalósításban nem is fontos, hogy a tömbnek neve legyen, megoldható a feladat úgy is, hogy a malloc függvénnyel vagy más módon az operációs rendszertől kérünk egy név nélküli tárterület elejét kijelölő mutatót.
Az allocbuf használatához további információk kellenek. A programban egy allocp mutatót fogunk használni, ami kijelöli az allocbuf következő szabad helyét. Ha az alloc-tól n karakternyi helyet kérünk, akkor az ellenőrzi, hogy van-e még ennyi szabad hely az allocbuf-ban. Ha igen, akkor az alloc visszatér az allocp aktuális értékével (azaz a szabad terület kezdetével), majd ezután n értékével megnöveli, hogy a következő szabad helyre mutasson. Ha az allocbuf-ban nincs elegendő hely, akkor az alloc nulla értékkel tér vissza. Az afree függvény egyszerűen p értékre állítja az allocp mutatót, ha p az allocbuff-ba mutat. A puffer kezelését a következő egyszerű ábra mutatja.
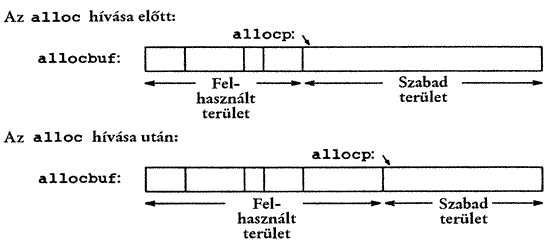
A program:
#define ALLOCSIZE 10000 static char allocbuf[ALLOCSIZE]; static char *allocp = allocbuf; char *alloc(int n) { if (allocbuf + ALLOCSIZE - allocp >= n) { allocp += n; return allocp - n; } else return 0; } void afree(char *p) { if (p >= allocbuf && p < allocbuf + ALLOCSIZE) allocp = p; }
A mutatót ugyanúgy lehet inicializálni, mint bármelyik más változót, de normális esetben csak a nullát vagy korábban definiált megfelelő típusú adatok címeit tartalmazó kifejezést rendelhetünk hozzá kezdeti értékül. A
static char *allocp = allocbuf;
deklaráció definiálja az allocp karakteres adathoz tartozó mutatót és egyben inicializálja is, hogy az az allocbuf kezdetére mutasson, ami a program indulásakor az első szabad hely. Helyette azt is írhattuk volna, hogy
static char *allocp = &allocbuf[0];
mivel a tömb neve egyben a nulladik indexű elemének a címe. A program vizsgáló része
if(allocbuf + ALLOCSIZE - allocp >= n) ellenőrzi, hogy a tömbben van-e elegendő hely n karakter számára. Ha igen, akkor az allocp legfeljebb eggyel mutat túl az allocbuf végén. Ha a helyigény kielégíthető, akkor az alloc az n karakteres blokk kezdetét kijelölő mutatóval tér vissza (figyeljük meg a függvény deklarációját). Ha nem, akkor az alloc egy jelzést ad vissza. A C nyelv garantálja, hogy egy adat címe soha nem nulla, így a visszatéréskor érzékelt nulla függvényérték a normálistól eltérő működést, azaz a szükséges hely hiányát jelzi.A mutatók és az egész számok nem felcserélhetők. Ez alól egyetlen kivétel van, a nulla: a nulla, mint állandó, hozzárendelhető egy mutatóhoz és egy mutató összehasonlítható a nulla állandóval. A nulla számkonstans helyett gyakran használják a NULL szimbolikus állandót, amivel a mutató speciális értékét jelzik. Ezek után a mutatókkal kapcsolatban mi is a NULL szimbolikus állandót fogjuk használni. A NULL az <stdio.h> headerben van definiálva.
Az
if(allocbuf + ALLOCSIZE - allocp >= n) és
if(p >= allocbuf && p < allocbuf + ALLOCSIZE) formájú vizsgálatok a címaritmetika számos fontos tulajdonságára mutatnak rá. Ha p és q ugyanazon tömb elemeire mutatnak, akkor az ==, !=, <, >, <= stb. relációk helyesen működnek. Például a
p < q
reláció igaz, ha p a tömb egy korábbi (kisebb indexű) elemére mutat, mint q. Bármely mutató értelmes módon egyenlőségre vagy nem egyenlőségre összehasonlítható nullával. Ha viszont nem ugyanazon tömb mutatóit használjuk aritmetikai kifejezésekben vagy relációkban, akkor az eredmény értelmetlen (amit vagy azonnal észreveszünk, vagy nem). A szabály alól csak egyetlen kivétel van: egy tömb vége utáni első elem címét a címaritmetika még képes feldolgozni.Mint már láttuk, egy mutatót és egy egész számot szabad összeadni vagy kivonni. A
p + n
konstrukció a p mutatóval aktuálisan kijelölt utáni n-edik objektumot jelenti. Ez attól függetlenül igaz, hogy p milyen típusú objektumot címez meg, mivel a fordítóprogram n-t olyan egységekben számolja, mint a p-vel megcímzett objektum mérete (és ezt a p deklarációja határozza meg). Ha pl. az adott számítógépen az int típusú adat négy bájtos, akkor int adatok esetén a mérték négy.A mutatók kivonása szintén megengedett: ha p és q ugyanazon tömb elemeit címzik, és p < q, akkor q – p + 1 a p és q közötti elemek száma (a határokat is beleértve). Ezt a tényt kihasználva írjuk meg a karaktersorozat hosszát megadó strlen függvény egy újabb változatát!
int strlen (char *s) { char *p = s; while (*p != '\0') p++; return p - s; }
A deklarációban a p kezdeti értékeként s-t adtuk meg, így p a karaktersorozat első elemére mutat. A while ciklusban egyenként vizsgáljuk a karaktereket, amíg el nem érünk a ‘\0‘ végértékig. Mivel p karakterekre mutat, p++ mindig a következő karakterre lépteti p-t, és a vizsgálat végén p – s a megvizsgált karakterek számát adja. (A karaktersorozatban lévő karakterek száma túl nagy lehet ahhoz, hogy int típusú adatként kezeljük. Az <stddef.h> headerben definiálva van egy ptrdiff_t típus, ami elegendően nagy ahhoz, hogy két mutató előjeles különbségét tárolja. Ha nagyon gondosak akarunk lenni, akkor az strlen visszatérési típusát a standard könyvtári változatnak megfelelően size_t típusnak választjuk. A size_t egy előjel nélküli egész adattípus, amelyet a sizeof operátor ad visszatérési értékként.)A címaritmetika működése következetes: ha float típusú adatokkal dolgozunk, amelyek több helyet igényelnek, mint a char típusúak, és p egy float típusú adatot címző mutató, akkor p++ a következő float típusú adatot jelöli ki. Így minden további nélkül megírhatjuk az alloc függvény egy másik változatát, amelyben a char adattípus helyett float adattípust tárolunk. Ehhez mindössze az alloc és a free függvényekben a char szót float-ra kell átírni. Minden mutatókkal végzett művelet automatikusan figyelembe veszi a megcímzett objektum méretét.
A mutatók esetén megengedett műveletek az azonos típusú mutatók közötti értékadás, mutatók és egészek közötti összeadás vagy kivonás, két azonos tömbre értelmezett mutató kivonása vagy összehasonlítása, valamint mutató értékadása vagy összehasonlítása nullával. Minden más mutatókra vonatkozó aritmetikai művelet tilos. Nem lehet két mutatót összeadni, szorozni, osztani, léptetni vagy maszkolni, és ugyancsak tilos mutatóhoz float vagy double típusú értéket hozzáadni. A szabályok alól csak a void* a kivétel, amely rákényszerített típusmegadás (cast) nélkül egy adott típusú mutatóhoz egy másik típusú mutatót rendel.
5.5. Karaktermutatók és függvények
Az
"Ez egy karaktersorozat"
alakban írt karaktersorozat állandók valójában karakterekből álló tömbök, amelyeket a belső ábrázolásban egy null-karakter (‘\0‘) zár. A program a karaktersorozat végét a null-karakter keresésével találja meg. Ezt a belső ábrázolást használva a karaktersorozat tárolásához szükséges hely csak egy karakterrel több, mint az idézőjelek közötti karakterek száma. A karaktersorozat állandók a leggyakrabban függvények argumentumaként fordulnak elő, mint pl. a
printf("Halló mindenki!\n");
függvényben. Az ehhez hasonló karaktersorozatokhoz a program karakteres mutatón keresztül fér hozzá, azaz a printf függvény megkapja a karaktersorozat kezdetének mutatóját. Általánosan igaz, hogy a program a karaktersorozathoz az első elemét kijelölő mutatón keresztül fér hozzá.A karaktersorozat természetesen nem csak függvények argumentumaként fordulhat elő. Ha a puzenet változót úgy deklaráltuk, hogy
char *puzenet; akkor a
puzenet = "Itt az idő!"
utasítás a puzenet-hez a karaktersorozatot tartalmazó tömb mutatóját rendeli. Ez valójában nem karaktersorozat-másolás, csak a mutatók rendelődnek egymáshoz. A C nyelvben nincs olyan operátor, amellyel egy karaktersorozat, mint egyetlen objektum, feldolgozható lenne.A következő két definíció között lényeges különbség van:
char auzenet = "Itt az idő!"; char *puzenet = "Itt az idő!";
Az auzenet egy tömb, ami elegendően nagy ahhoz, hogy a karaktersorozatot és a ‘\0‘ végjelzést tárolni tudja, és a tömbnek az „Itt az idő!” karaktersorozatot adjuk kezdeti értékül. Másrészt a puzenet egy mutató, amelyhez egy karaktersorozat állandót megcímző kezdőértéket rendelünk. Ez a mutató természetesen módosítható, és akkor más objektumot fog megcímezni, viszont a karaktersorozat módosítása definiálatlan eredményt ad. A kétféle definíció térbeli elhelyezkedését a következő vázlat mutatja:
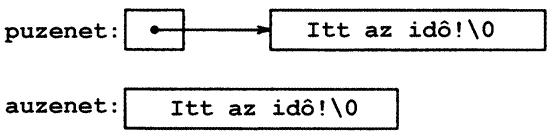
A mutatók és tömbök használatának néhány kérdését két hasznos függvényen keresztül mutatjuk be. A függvények a standard könyvtárban megtalálhatók. Az első, strcpy(s, t) függvény a t karaktersorozatot az s karaktersorozatba másolja át. Jó lenne, ha azt írhatnánk, hogy s = t, de ez csak a mutatót másolja át, magát a karaktersorozatot nem. A karaktersorozat átmásolásához egy ciklus szükséges. A karaktersorozatot átmásoló strcpy függvény karakteres tömbökkel megvalósított változata:
void strcpy(char *s, char *t) { int i; i = 0; while ((s[i] = t[i]) != '\0') i++; }
A következőkben bemutatjuk az strcpy függvény mutatókkal megvalósított változatát:
void strcpy(char *s, char *t) { while ((*s = *t) != '\0') { s++; t++; } }
Mivel a C nyelv az argumentumokat érték szerint adja át, így az strcpy tetszés szerint használhatja az s és t paramétereket (ill. azok helyi másolatait). A program a szokásos módon inicializálja a mutatókat, majd ezek karakterenként végighaladnak a tömbökön, mindaddig, amíg a t karaktersorozatot lezáró ‘\0‘ át nem másolódik s-be.A gyakorlatban az strcpy függvényt nem az előző módon írnánk meg. Egy gyakorlott C programozó inkább a következő változatot részesítené előnyben:
void strcpy(char *s, char *t) { while((*s++ = *t++) != '\0') ; }
Ez a változat az s és t mutatók inkrementálását a ciklus vizsgáló részébe építi be. A *t++ értéke az a karakter, amelyre t az inkrementálás előtt mutat. A postfix inkrementálás a karakter feldolgozásának befejeztéig nem változtatja meg t-t. Ugyanígy a karakter a régi s által kijelölt pozícióba tárolódik, még s inkrementálása előtt. Az átmásolt karaktereket a program a ‘\0‘ végjelzéssel hasonlítja össze és ez vezérli a ciklust. Mindezek hatására t összes karaktere, a lezáró ‘\0‘ végjelet is beleértve átkerül s-be.A programot vizsgálva megfigyelhető, hogy a ‘\0‘ végjelzéssel való összehasonlítás redundáns, ezért a függvény még tovább rövidített változata úgy írható be, hogy
void strcpy(char *s, char *t) { while (*s++ = *t++) ; }
Ez a változat első ránézésre nagyon titokzatosnak tűnik, de a jelölés nagyon kényelmes, ezért célszerű elsajátítani. Különböző programokban gyakran találkozhatunk vele.
Az strcpy függvény a standard könyvtárban (a <string.h> headerben) található, és visszatérési értéke az átmásolt karaktersorozat.A példaként megírt második függvény az strcmp(s, t), amely az s és t karaktersorozatokat hasonlítja össze, és visszatérési értéke negatív, nulla vagy pozitív attól függően, hogy az s lexikografikusan kisebb, egyenlő vagy nagyobb t-nél. (A lexikografikus sorrendet úgy kapjuk, hogy a karaktersorozatokat a gép belső karakterkészletének megfelelően – tágabb értelemben, a különböző jeleket is beleértve – ábécésorrendbe rendezzük. A kisebb, egyenlő vagy nagyobb reláció ekkor az ábécében elfoglalt helyek viszonyát jelzi.) Ezt az értéket úgy kapjuk meg, hogy az első olyan helyen, ahol s és t különbözik, kivonjuk egymásból a két karaktert. A program tömbindexeléssel megvalósított változata:
int strcmp(char*s, char *t) { int i; for (i = 0; s[i] == t[i]; i++) if (s[i] == '\0') return 0; return s[i] - t[i]; }
A függvény mutatókkal megvalósított változata:
int strcmp(char *s, char *t) { for ( ; *s == *t; s++, t++) if (*s == '\0') return 0; return *s - *t; }
Mivel a ++ és — prefix és postfix formában egyaránt használhatók, ezért a * , ill. a ++ és — operátorok, ritkán, de más kombinációban is előfordulhatnak. Például a
*--p
a p-vel megcímzett karakter elővétele előtt dekrementálja p-t. Még néhány fontosabb kombináció:
*p++ = val; val = *--p;
Az előző két példát érdemes megjegyezni, mivel a verem kezelésének alapműveletei.Az strcpy és strcmp függvények deklarációit a standard könyvtár tartalmazza, és több más karaktersorozat-kezelő függvény deklarációjával együtt a <string.h> headerben találhatók.
5.3. gyakorlat. Írja meg a 2. fejezetben bemutatott strcat(s, t) függvény mutatóval megvalósított változatát! Az strcat(s, t) függvény a t karaktersorozatot az s karaktersorozat végéhez másolja.
5.4. gyakorlat. Írjon strend(s, t) néven függvényt, amely 1 értékkel tér vissza, ha a t karaktersorozat megtalálható az s karaktersorozat végén, és 0 értékkel, ha nem!
5.5. gyakorlat. Írja meg az strncpy, strncat és strncmp könyvtári függvények saját változatát! Ezek a függvények az argumentumként megadott karaktersorozat legfeljebb első n karakterével végeznek műveletet, pl. az strncpy(s, t, n) a t karaktersorozat legfeljebb első n karakterét másolja s-be. (A könyvtári függvények leírása a B. Függelékben található.)
5.6. gyakorlat. Írjuk át a korábbi fejezetek erre alkalmas példaprogramjait úgy, hogy indexelt tömbök helyett mutatókat használjunk! Erre kiválóan alkalmas az 1. és 4. fejezetben megírt getline, a 2., 3. és 4. fejezetben megírt atoi, itoa és minden változata, a 3. fejezetben használt reverse, valamint a 4. fejezetben használt strindex és getop függvény.
5.6. Mutatótömbök és mutatókat megcímző mutatók
Mivel a mutatók maguk is változók, ezért minden további nélkül tárolhatók tömbökben, csakúgy, mint bármely más változó. Ennek bemutatása céljából írjunk programot, amely szövegsorokat ábécésorrendbe rendez. (Ez a UNIX sort rendezőprogramjának egyszerűsített változata lesz.)A 3. fejezetben már bemutattuk a Shell-féle algoritmus alapján működő rendezőprogramot és a 4. fejezetben annak javított változatát, a quicksort programot. A példában ugyanezeket az algoritmusokat fogjuk használni, azzal az eltéréssel, hogy most változó hosszúságú szövegsorokat rendezünk az egész számok helyett. Ez lényeges különbség, mivel a szövegsorokat nem hasonlíthatjuk össze vagy mozgathatjuk egyetlen művelettel. Olyan adatábrázolásra van szükség, ami lehetővé teszi a változó hosszúságú szövegsorok hatékony és kényelmes kezelését.
Ez a mutatókból álló tömbökkel valósítható meg legegyszerűbben. Ha a rendezendő sorokat egy hosszú karakteres tömbben, egymáshoz illesztve tároljuk, akkor az egyes sorok az első karakterüket megcímző mutatón keresztül érhetők el. Ezek a mutatók egy tömbben tárolhatók. Két sor úgy hasonlítható össze, hogy átadjuk a mutatóikat az strcmp függvénynek. Ha két sor rossz sorrendben van és fel kell cserélni őket, akkor csak a mutatóikat cseréljük a mutatótömbben, és nem pedig magukat a sorokat. Az elvet a következő ábra szemlélteti:

Ezzel a szervezéssel elkerülhetjük azt a kettős problémát, amit a bonyolult tárolókezelés és a szövegsorok tényleges mozgatásából adódó nagy műveletigény jelent. A rendezési folyamat három lépésből áll:
az összes sor beolvasása a sorok rendezése a rendezett sorok kiíratása
A szokásoknak megfelelően a programot a feladat természetes felosztása szerint tagoljuk, és a main csak az egyes programrészeket vezérli. Pillanatnyilag ne foglalkozzunk magával a rendezéssel, hanem koncentráljunk az adatszerkezetre, valamint az adatok bevitelére és kiírására.Az adatbeviteli programrész beolvassa és eltárolja az egyes sorok karaktereit, valamint ezzel egy időben létrehozza a sorok mutatóit tartalmazó tömböt. Ugyancsak ennek a programrésznek a feladata a sorok számlálása, mivel a sorok számára szükség lesz a rendezés és a kinyomtatás során. Mivel az adatbeviteli programrész csak véges sok sort képes beolvasni, ezért egy adott korlátnál több sor beérkezése esetén -1 értékkel tér vissza (illegális számú sor jelzése).
A sorokat kiíró programrész olyan sorrendben fogja kiírni a szövegsorokat, amilyen sorrendben a mutatóik előfordulnak a mutatótömbben. A program eddig tárgyalt részei:
#include <stdio.h> #include <string.h> #define MAXSOR 5000 char *sorptr[MAXSOR]; int readlines(char *sorptr[], int nsor); void writelines(char *sorptr[], int nsor); void qsort(char *sorptr[], int bal, int jobb); main() { int nsor; if ((nsor = readlines(sorptr, MAXSOR)) >=0) { qsort (sorptr, 0, nsor-1); writelines(sorptr, nsor); return 0; } else { printf ("Hiba: túl sok rendezendő sor\n"); return 1; } } #define MAXHOSSZ 1000 int getline(char *, int); char *alloc(int); int readlines(char *sorptr[], int maxsor) { int hossz, nsor; char *p, sor[MAXHOSSZ]; nsor = 0; while ((hossz = getline(sor, MAXHOSSZ)) > 0) if (nsor >= maxsor || (p = alloc(hossz)) == NULL) return -1; else { sor[hossz-1] = '\0'; strcpy(p, sor); sorptr[nsor++] = p; } return nsor; } void writelines(char *sorptr[], int nsor) { int i; for (i =0; i < nsor; i++) printf ("%s\n", sorptr[i]); }
A program használja az 1.9. pontban leírt getline függvényt.A legfontosabb újdonsággal a sorptr deklarációjában találkozunk. A
char *sorptr[MAXSOR] azt mondja, hogy a sorptr egy tömb, amelynek MAXSOR számú eleme van és minden elem egy char típushoz tartozó mutató. Így a sorptr[i] egy karakterhez tartozó mutató és *sorptr[i] pedig az i-ediknek eltárolt szövegsor első karakterének mutatója.Mivel sorptr maga is egy tömb neve, mutatóként kezelhető ugyanúgy, mint a korábbi példákban a tömbnevek, ezért a writelines függvényt úgy is megírhatjuk, hogy
void writelines(char *sorptr[], int nsor) { while (nsor-- > 0) printf ("%s\n", *sorptr++); }
Kezdetben *sorptr az első sorra mutat, majd az inkrementálás hatására a következő sorra lép, amíg csak n sor le nem számlálódik.Miután a sorok beolvasását, ill. kiíratását elintéztük, rátérhetünk a rendezésre. A 4. fejezetben bemutatott quicksort programot kissé meg kell változtatnunk: módosítani kell a deklarációkat és az összehasonlítást az strcmp függvény hívásával kell elvégeznünk. Az algoritmus változatlan marad, ezért bízhatunk benne, hogy továbbra is működni fog.
void qsort(char *v[], int bal, int jobb) { int i, utolso; void swap(char *v[], int i, int j); if (bal >= jobb) return; swap(v, bal, (bal + jobb)/2); utolso = bal; for (i = bal + 1; i <= jobb; i++) if (strcmp(v[i], v[bal]) < 0) swap(v, ++utolso, i); swap(v, bal, utolso); qsort(v, bal, utolso-1); qsort(v, utolso+1, jobb); }
A swap függvényt is csak triviális módon kell megváltoztatni, a deklaráció értelemszerű módosításával:
void swap(char *v[], int i, int j) { char *temp; temp = v[i]; v[i] = v[j]; v[j] = temp; }
Mivel v (a sorptr) bármelyik egyedi eleme egy karakteres mutató, így temp is az kell, hogy legyen az értékadás miatt.
5.7. gyakorlat. Módosítsuk a readlines függvényt úgy, hogy a beolvasott sorokat a main által létrehozott tömbben tárolja, és ne az alloc függvényen keresztül kérjen mindig helyet a sor számára! A program mennyivel lesz gyorsabb, ha elmarad az alloc hívása?
5.7. Többdimenziós tömbök
A C nyelv lehetővé teszi a derékszögű többdimenziós tömbök alkalmazását, bár ezeket sokkal ritkábban használják, mint a mutatótömböket. Ebben a pontban bemutatjuk a többdimenziós tömbök tulajdonságait.Vizsgáljuk meg a hónap napjairól az év napjaira vagy fordítva történő adatátalakítás feladatát! Például március 1. egy nem szökőév 60. napja, szökőévben pedig a 61. nap. Az átalakításhoz definiáljunk két függvényt: a day_of_year függvény a hónap napjait az év napjaivá alakítja, a month_day függvény pedig az év napjait a hónap napjaivá. Mivel a month_day függvény két értéket (hónap és nap) számol, így a hónap és nap argumentum mutató lesz. A
month day(1988, &h, &n)
függvényhívás h értékét 2-re, n értékét 29-re állítja be (1988. február 29.).Mindkét függvénynek azonos információra van szüksége: egy táblázatra, ami tartalmazza az egyes hónapokban lévő napok számát. Mivel a hónapok napjainak száma más és más szökőévben és nem szökőévben, ezért egyszerűbb a szökőév és nem szökőév adatait egy kétdimenziós tömb két sorában tárolni, mint mindig vizsgálni, hogy februárban milyen adattal kell dolgozni. Az adatátalakítást végző függvények és az átalakításhoz szükséges tömb:
static char naptab[2][13] = { {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}, {0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31} }; int day_of_year(int ev, int ho, int nap) { int i, szoko; szoko = ev%4 == 0 && ev%100 != 0 || ev%400 == 0; for (i = 1; i < ho; i++) nap += naptab[szoko][i]; return nap; } void month_day(int ev, int evnap, int *pho, int *pnap) { int i, szoko; szoko = ev%4 == 0 && ev%100 != 0 || ev%400 == 0; for (i = 1; evnap >naptab[szoko][i]; i++) evnap -= naptab[szoko][i]; *pho = i; *pnap = evnap; }
Emlékezzünk vissza a logikai kifejezések számértékéről mondottakra: az nulla, ha a kifejezés hamis, és egy, ha igaz. Ezt használtuk ki a szoko meghatározásánál, és az így kapott 0 vagy 1 érték felhasználható a naptab indexelésére.A naptab tömb a day_of_year és month_day függvények számára külső változó, így mindkettő használhatja. A naptab tömb elemeit char-ként adtuk meg, hogy ezzel is megmutassuk a char típusú adat nemcsak karakterek, hanem kis egész számok tárolására is alkalmas.
A naptab az első kétdimenziós tömb, amivel eddig találkoztunk. A C nyelvben a kétdimenziós tömb valójában egy egydimenziós tömb, amelynek mindegyik eleme szintén egy tömb. Ezért kell az indexeket
naptab[i][j] alakba írni a más nyelvekben megszokott
naptab[i, j] alak helyett. A kétdimenziós tömbben az elemek sorfolytonosan tárolódnak, ezért a jobbra az utolsó index (oszlopindex) változik a leggyorsabban, ha az elemeket a tárolás sorrendjében címezzük.A tömböt kapcsos zárójelek között elhelyezett kezdeti értékekkel inicializáljuk, és a kétdimenziós tömb egyes sorait a megfelelő allisták inicializálják. A naptab tömböt egy nulla tartalmú oszloppal kezdtük, hogy az 1-től 12-ig terjedő hónapszámmal természetes módon indexelhessük a 0…11 indexek helyett. Mivel a példában a felesleges oszlop nem növeli számottevően a program helyfoglalását, ezért inkább ezt a megoldást választottuk, mint az indexek átkódolását.
Ha egy kétdimenziós tömböt átadunk egy függvénynek, akkor a függvényben lévő paraméterdeklarációban meg kell mondani az oszlopok számát. A sorok száma közömbös, mivel (az egydimenziós tömbökhöz hasonlóan) itt is a sorok alkotta tömb mutatóját adjuk át (ami jelen esetben 13 int típusú adatot tartalmazó tömbre mutat). Ezért ha a naptab tömböt pl. egy f függvénynek adnánk át, akkor az f deklarációja
f(int naptab[2][13]) {...} alakú, amit úgy is írhatnánk, hogy
f(int naptab[][13]) {...} mivel a sorok száma közömbös, vagy
f(int (*naptab)[13]){...} alakban, ami azt fejezi ki, hogy a paraméter egy mutató, ami 13 egész adatból álló tömbre mutat. A kerek zárójel szükséges, mivel a [ ] szögletes zárójelek nagyobb precedenciájúak, mint a *. A zárójel nélküli
int *naptab[13] deklaráció 13 mutatóból álló tömböt deklarálna, amelynek mindegyik eleme egy egész típusú adatra mutat. Az ehhez hasonló összetett deklarációk kérdésével az 5.12. pontban még foglalkozunk.
5.8. gyakorlat. A day_of_year és month_day függvényekben nincs hibaellenőrzés. Küszöböljük ki ezt a hiányosságot!
5.8. Mutatótömbök inicializálása
Írjunk egy month_name(n) függvényt, amely egy, az n-edik hónap nevét tartalmazó karaktersorozatot címző mutatót ad visszatérési értékként. Ez a belső static tárolási osztályú tömb ideális alkalmazási lehetősége! A month_name függvény karaktersorozatokból álló saját tömböt tartalmaz, és hívásakor a megfelelő mutatóval tér vissza. A feladat megoldása kapcsán megmutatjuk, hogy hogyan inicializálható a nevekből álló tömb.A szintaxis hasonló a korábban használt inicializálások szintaxisához:
char *month_name(int n) { static char *nev[] = { "Illegális hónapnév", "Január", "Február", "Március", "Április", "Május", "Június", "Július", "Augusztus", "Szeptember", "Október", "November", "December" }; return (n < 1 || n > 12) ? nev[0] : nev[n]; }
A karakteres mutatók tömbjét alkotó nev deklarációja ugyanolyan, mint a sorptr deklarációja volt a rendezőprogramban. Az eltérés csak az, hogy a kezdeti értékek most karaktersorozatok, amelyek hozzá vannak rendelve a tömb megfelelő eleméhez. Az i-edik karaktersorozat valahol a tárolóban helyezkedik el (nem tudjuk, hogy pontosan hol, de ez nem is érdekes) és a mutatója van a nev[i] helyen. Mivel a nev tömb méretét nem specifikáltuk, a fordítóprogram megszámolja a kezdeti értékeket és a kívánt helyre beírja a helyes számot.
5.9. Mutatók és többdimenziós tömbök
A kezdő C programozókat gyakran megzavarja a kétdimenziós tömb és a mutatókból álló tömb (mint pl. a nev az előző példában) közötti különbség. Ha pl. adott a következő két definíció:
int a[10][20]; int *b[10];
akkor az a[3][4] és b[3][4] mindegyike szintaktikailag helyes hivatkozás egy int típusú adatra. De a valójában egy kétdimenziós tömb: a definíció szerint 200 int méretű tárolóhelyet foglalunk le a számára, és egy elemének tényleges helyét mátrixos indexeléssel, mint 20*sor+oszlop határozzuk meg az a[sor][oszlop] logikai indexelés alapján. A b-re vonatkozó definíció csak 10 mutató számára foglal helyet és nem rendel hozzájuk kezdeti értéket. Az inicializálást explicit módon, statikusan vagy a programban kell elvégeznünk. Feltételezve, hogy b minden eleme egy 20 elemű tömbre mutat, akkor ez a tárolóban 200 int változónyi helyet igényel, amihez még hozzájön a 10 mutató helyigénye. A mutatótömbnek van egy lényeges előnye: az általa címzett tömb sorai különböző hosszúságúak lehetnek. Így a b egyes elemei nem szükségképpen mutatnak egy 20 elemű vektorra, lehet olyan, amelyik 2 elemre, a másik 5 elemre, sőt olyan is, amelyik 0 elemre mutat.Bár az előbbi fejtegetésben mi mindig egész típusú adatokról beszéltünk, a mutatótömbök leggyakoribb alkalmazása mégis az, amikor elemeik különböző hosszúságú karaktersorozatokra mutatnak (mint pl. a month_name függvényben). Az elmondottak jól láthatók az alábbi deklarációk és a hozzájuk tartozó, tárbeli elhelyezkedést szemléltető ábrák alapján. A mutatótömb:
char *nev[] = { "Illegális hónap", "Jan", "Febr", "Márc" }; 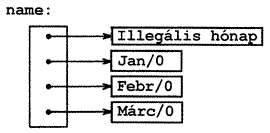
A kétdimenziós, karaktersorozatokat tároló tömb:
char anev[][15] = { "Illegális hónap", "Jan", "Febr", "Márc" } ; 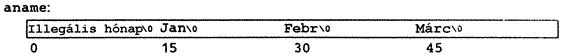
5.9. gyakorlat. Módosítsuk a day_of_year és month_day függvényeket úgy, hogy indexelés helyett mutatókat használjanak!
5.10. Parancssor-argumentumok
A C nyelvet támogató környezetben lehetőségünk van a programnak parancssor-argumentumokat vagy paramétereket átadni a végrehajtás megkezdésekor. Amikor a végrehajtás kezdetekor a rendszer a main-t hívja, akkor a hívásban két argumentum szerepel. Az első (amit argc-nek szokás nevezni) megadja a parancssor-argumentumok számát, amellyel a programot hívtuk. A második (amit argv-nek szokás nevezni) egy karaktersorozatokat tartalmazó tömböt címző mutató. A tömb tartalmazza a program hívásakor átadandó parancssor-argumentumokat (minden argumentum egy karaktersorozat). Ezeket a karaktersorozatokat általában többszintű mutatóhasználattal kezeljük.Az elmondottakat a legegyszerűbben az echo program mutatja, amely egyszerűen visszaírja az egy sorban megjelenő, egymástól szóközzel elválasztott parancssor-argumentumokat. Az a parancs, hogy
echo Halló mindenki!
egyszerűen kiírja a kimenetre, hogy
Halló mindenki!
Megállapodás szerint az argv[0] az a név, amellyel a programot hívták, így argc legalább 1. Ha argc egy, akkor a program neve után nincs parancssor-argumentum. A mi példánkban argc értéke három, és az argv[0], argc[1], ill. argv[2] rendre az „echo”, „Halló”, ill. „mindenki!” karaktersorozatokat tartalmazza. A sorban az első opcionális argumentum az argv[1] és az utolsó az argv[argc-1]. Mindezeken kívül a szabvány megköveteli, hogy argv[argv] NULL értékű mutató legyen. Az elmondottakat az alábbi ábra szemlélteti.
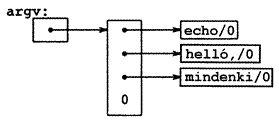
Az echo program első változata az argv-t karakteres mutatók tömbjeként kezeli.
#include <stdio.h> main (int argc, char *argv[]) { int i; for (i = 1; i < argc; i++) printf("%s%s", argv[i], (i < argc-1) ? " " : ""); printf("\n"); return 0; }
Mivel argv egy mutatótömb mutatója, ezért célszerűbb minden műveletet mutatókkal és nem indexelt tömbökkel végezni. A program következő változata ezért char típusú adatokat címző mutatók mutatóját, az argv-t inkrementálja, a argc-t pedig lefelé számlálja.
#include <stdio.h> main (int argc, char *argv []) { while(--argc > 0) printf("%s%s", *++argv, (argc > 1) ? " " : ""); printf("\n"); return 0; }
Mivel argv az argumentumok karaktersorozataiból álló tömb kezdetét kijelölő mutatók mutatója, inkrementálása (++argv) után az eredeti argv[0] helyett az argv[1]-re fog mutatni, argv az egymást követő inkrementálások hatására mindig a következő argumentumot fogja megcímezni és *argv ekkor az argumentum mutatója lesz. Ugyanakkor argc dekrementálódik, és ha értéke nulla lesz, akkor már nincs további kiírandó argumentum.A printf utasítást úgy is írhattuk volna, hogy
printf((argc > 1) ? "%s " : "%s", *++argv); Ez szintén azt példázza, hogy a printf argumentuma kifejezés is lehet.A második példánk a 4.1. pontban ismertetett mintakereső program bővített változata. Ha visszagondolunk a programra, akkor emlékezhetünk rá, hogy a keresett minta mélyen a programba van beágyazva (karakteres állandóként), ami nem túl szerencsés megoldás. A következőkben a UNIX rendszer grep segédprogramjának elvét követve a programot úgy változtattuk meg, hogy a keresendő mintát a parancssor első argumentumaként adhassuk meg. A módosított find program:
#include <stdio.h> #include <string.h> #define MAXSOR 1000 int getline(char *sor, int max); main(int argc, char *argv[]) { char sor[MAXSOR]; int talalt = 0; if (argc != 2) printf("Mintakeresés\n"); else while (getline(sor, MAXSOR) > 0) if (strstr(sor, argv[1])!= NULL) { printf("%s", sor); talalt++; } }
A standard könyvtár strstr(s, t) függvénye egy mutatóval tér vissza, amely a t karaktersorozat s-beli első előfordulásának helyére mutat, vagy a NULL értékkel, ha t nem fordul elő s-ben. Az strstr függvény a <string.h> headerben van deklarálva.Most a programot finomítsuk tovább, hogy újabb mutatókkal kapcsolatos példákat készíthessünk. Tegyük fel, hogy a program hívásakor két argumentumot engedünk meg. Az egyik jelentse azt, hogy „írj ki minden sort, kivéve azokat, amelyekben a keresett minta megtalálható”, a másik pedig azt, hogy „írd ki minden sor elé a sorszámot”.
A UNIX rendszer alatt futó C nyelvű programok esetén a programnév után opcionálisan megadható paraméterek vagy jelzők (flagek) megállapodás szerint a mínusz jellel kezdődnek. Ha a -x paramétert választjuk az inverz kiírási feltétel jelzésére (ne írja ki azokat a sorokat, amiben megtalálható a minta) és -n paramétert a sorszámozás jelzésére, akkor a teljes parancs:
find -x -n minta
alakú lesz, és hatására kiíródik minden olyan sor, amelyben a keresett minta nem található meg és a sorok előtt megjelenik a sorszám.Az opcionális argumentumok sorrendje tetszőleges kell legyen, és a program további (nem a paramétereket feldolgozó) részének működése nem függhet a megadott argumentumok számától. A felhasználók számára kényelmes lehet, hogy az argumentumok kombinálhatók a
find -xn minta
alakban. A továbbfejlesztett program:
#include <stdio.h> #include <string.h> #define MAXSOR 1000 int getline(char *sor, int max); main(int argc, char *argv[]) { char sor[MAXSOR]; long sorszam = 0; int c, kiveve = 0, szam = 0, talalt = 0; while (--argc > 0 && (*++argv)[0] == '-') while (c = *++argv[0]) switch (c) { case 'x': kiveve = 1; break; case 'n': szam = 1; break; default: printf("find: illegális opció %c\n", c); argc = 0; talalt = -1; break; } if (argc != 1) printf("find -x -n minta \n"); else while (getline(sor, MAXSOR) > 0) { sorszam++; if ((strstr(sor, *argv) != NULL)!= kiveve) { if(szam) printf("%1d:", sorszam); printf("%s", sor); talalt++; } } return talalt; }
Minden egyes opcionális argumentum elővétele előtt az argc dekrementálódik és az argv inkrementálódik. A ciklus végén – ha nem volt hiba – az argc tartalma megmondja, hogy hány argumentum maradt feldolgozatlanul és argv ezek közül az elsőre mutat, így argc akár 1 is lehet, és ekkor *argv a keresendő mintára fog mutatni. Mivel *++argv a karaktersorozatként megadott argumentum mutatója, ezért a (*++argv)[0] a karaktersorozat első karaktere. (Egy másik, szintaktikailag helyes forma az első karakter kijelölésére a **++argv.) Mint már említettük, a [] szorosabban kötődik, mint a * és a ++, ezért a zárójelekre szükség van. Elhagyva azokat a kifejezés *++(argv[0]) formában értékelődne ki, ami mást jelent. Más a helyzet, amikor a belső ciklust használjuk, aminek az a feladata, hogy végighaladjon egy kiválasztott argumentum karaktersorozatán! Itt a *++argv[0] az argv[0] mutatót inkrementálja!Az itt bemutatottaknál ritkán használunk bonyolultabb mutatós kifejezéseket. Ha mégis szükség lenne ilyenekre, akkor célszerű azokat két vagy három egyszerűbb lépésre bontani.
5.10. gyakorlat. Írjuk meg az expr programot, amely kiértékeli a parancssor-argumentumban megadott fordított lengyel jelölésmódú kifejezést! A parancssorban az egyes operátorokat és operandusokat szóköz választja el egymástól, pl. az
expr 2 3 4 + *
formában, ami a 2*(3+4) kifejezésnek felel meg.5.11. gyakorlat. Módosítsuk az 1. fejezetben megírt entab és detab programot úgy, hogy a tabulátorbeállítási pozíciók listáját a parancssor-argumentumból vegye! Használjuk az alapesetnek megfelelő működést, ha nincs argumentum!
5.12. gyakorlat. Bővítsük az entab és detab programokat úgy, hogy értelmezni tudják az
entab -m +n
rövidített jelölést! A bővített forma jelentése, hogy az m-edik oszloptól kezdve iktasson be tabulátorokat minden n-edik oszlophoz. A program a felhasználó szempontjából kényelmes módon működjön, ha nem adunk meg argumentumot!5.13. gyakorlat. Írjuk meg a tail programot, amely kinyomtatja az utolsó n bemeneti sort! Alapfeltételezés szerint legyen n=10, de tegyük lehetővé n változtatását egy opcionális argumentummal pl. a
tail -n
formában. (Ennek hatására az utolsón sor íródjon ki.) A program viselkedjen ésszerűen akkor is, ha a bemenet vagy az n értéke ésszerűtlen. A programot úgy írjuk meg, hogy a lehető legjobban használja a rendelkezésére álló tárterületet: a szövegsorokat a rendezőprogramnál leírt módon tároljuk és ne rögzített méretű kétdimenziós tömbként.
5.11. Függvényeket megcímző mutatók
A C nyelvben a függvények ugyan nem változók, de azért lehetséges hozzájuk mutatót definiálni, amivel minden, a mutatókra megengedett művelet elvégezhető (szerepelhet értékadásban, elhelyezhető egy tömbben, átadható egy függvénynek argumentumként, lehet a függvény visszatérési értéke stb.). A függvényekhez rendelt mutatók használatát a korábban megírt rendezőprogram módosított változatán mutatjuk be. A rendezőprogramot alakítsuk át úgy, hogy a -n opcionális argumentum hatására a bemeneti sorokat ne lexikografikusan, hanem numerikusan rendezze.A rendezés általában három részből áll: összehasonlításból, ami meghatározza bármely objektumpár sorrendjét; cseréből, ami megfordítja az objektumok sorrendjét, valamint a rendező algoritmusból, ami mindaddig végzi az összehasonlítást és cserét, amíg minden objektum nem kerül a megfelelő sorrendbe. A rendező algoritmus független az összehasonlítás és a cserélés működésétől, így különböző összehasonlító és cserélő függvényeket használva különböző kritériumok szerint rendezhetünk. Ezt a lehetőséget használjuk ki az új rendezőprogram kialakításánál.
Két szövegsor lexikografikus összehasonlítását eredetileg a strcmp végezte. Most szükségünk lesz a numcmp függvényre, amely két sort a numerikus értéke alapján hasonlít össze és ugyanolyan módon tér vissza, mint a strcmp. Az összehasonlító függvényeket a main előtt deklaráljuk, és a megfelelő függvény mutatóját adjuk át a qsort függvénynek (ami a rendező algoritmust valósítja meg). Nem foglalkozunk a hibás argumentumok kezelésével, csak a fő feladatra, a mutatók átadására koncentrálunk.
#include <stdio.h> #include <string.h> #define MAXSOR 5000 char *sorptr[MAXSOR]; int readlines(char *sorptr[], int nsor); void writelines(char *sorptr[], int nsor); void qsort(void *sorptr[], int bal, int jobb, int (*comp) (void *, void *)); int numcmp(char *, char *); main(int argc, char *argv[]) { int nsor; int numeric = 0; if (argc > 1 && strcmp(argv[1], "-n") == 0) numeric = 1; if ((nsor = readlines(sorptr, MAXSOR)) >= 0) { qsort ((void **) sorptr, 0, nsor-1, (int (*)(void*, void*)) (numeric ? numcmp : strcmp)); writelines(sorptr, nsor); return 0; } else { printf("Túl sok rendezendő sor\n"); return 1; } }
A qsort hívásában a strcmp és numcmp függvények címei szerepelnek. Mivel ezek a nevek biztosan függvények nevei, ezért nincs szükség az & operátorra, ugyanúgy, ahogy a tömbök nevei előtt sem.Úgy módosítottuk a qsort programot, hogy képes legyen bármilyen adattípus feldolgozására, ne csak karaktersorozatokéra. Amint ezt a függvényprototípusban jeleztük, a qsort egy mutatókból álló tömböt, két egész típusú adatot és egy függvényt (két mutató típusú argumentummal) vár. A mutató típusú argumentumok megadásához a void * általános (generikus) mutatótípust használtuk. Bármely mutató átalakítható void * típusúvá, ill. abból visszaalakítható bármiféle információvesztés nélkül, ezért használtunk a qsort hívásánál void * típusú argumentumokat. A megfelelően kialakított típusmegadások garantálják a mutatók típusegyeztetését. Ez a program tényleges megvalósítására semmilyen hatással sincs, de biztosítja a fordítóprogram helyes működését.
Ezután nézzük a qsort függvény módosított változatát!
void qsort(void *v[], int bal, int jobb, int (*comp)(void *, void *)) { int i, utolso; void swap(void *v[], int, int); if (bal >= jobb) return; swap(v, bal, (bal + jobb)/2); utolso = bal; for (i = bal+1; i <= jobb; i++) if ((*comp) (v[i], v[bal]) < 0) swap(v, ++utolso, i); swap(v, bal, utolso); qsort(v, bal, utolso-1, comp); qsort(v, utolso+1, jobb, comp); }
A deklarációkat különös gonddal kell tanulmányozni! A qsort negyedik paramétere, az
int (*comp)(void *, void *)
azt mondja ki, hogy a comp egy függvényt címző mutató, amelynek két void * típusú argumentuma van és int típusú értékkel tér vissza. A comp függvény használata az
if ((*comp) (v[i], v[bal] < 0) sorban összhangban van a deklarációval: comp egy függvényhez tartozó mutató, így *comp maga a függvény, és
(*comp)(v[i], v[bal])
pedig annak hívása. A zárójelek feltétlenül szükségesek a helyes végrehajtási sorrend céljából. Ha elhagynánk őket, akkor az
int *comp(void *, void *)
definícióhoz jutnánk, ami azt mondja ki, hogy comp egy függvény, amely egy int típusú adatot megcímző mutatót ad vissza. Ez nyilvánvalóan mást jelent, mint az eredeti értelmezés.Korábban már bemutattuk a két karaktersorozatot összehasonlító strcmp függvényt, így most csak a numcmp függvénnyel foglalkozunk. A numcmp az első jegytől indulva számérték szerint hasonlít össze két karaktersorozatot. A numcmp az összehasonlításhoz a számokat tartalmazó karaktersorozatot az atof függvénnyel alakítja numerikus változóvá.
#include <stdlib.h> int numcmp(char *s1, char *s2) { double v1, v2; v1 = atof(s1); v2 = atof(s2); if (v1 < v2) return -1; else if (v1 > v2) return 1; else return 0; }
A két adatot a mutatóik felcserésével megcserélő swap függvény azonos a fejezet elején leírttal, kivéve, hogy a deklarációk void * típusra változtak.
void swap(void *v[], int i, int j) { void *temp; temp = v[i]; v[i] = v[j]; v[j] = temp; }
Az itt bemutatotton kívül még számtalan más opció is illeszthető a rendezőprogramhoz, ezek közül néhány jó gyakorló feladat lesz.
5.14. gyakorlat. Módosítsuk a rendezőprogramot úgy, hogy kezelni tudja a -r jelzést, amivel a fordított (csökkenő) irányú rendezést írjuk elő! Biztosítsuk, hogy a -r működjön a -n opcióval együtt is!
5.15. gyakorlat. A rendezőprogramot egészítsük ki a -f opcióval, ami egyesíti a nagy- és kisbetűket úgy, hogy a rendezésnél nem tesz különbséget közöttük! (Például A és a összehasonlítva legyen egyenlő.)
5.16. gyakorlat. A rendezőprogramot egészítsük ki a -d opcióval, aminek hatására csak a betűk, számjegyek és szóközök kerülnek összehasonlításra! Gondoskodjunk róla, hogy a -d opció működjön a -f opcióval együtt is!
5.17. gyakorlat. Egészítsük ki a rendezőprogramot mezőkezelési funkcióval, ami lehetővé teszi, hogy a rendezést sorokon belül kijelölt mezőkön hajtsuk végre! Engedjünk meg az egyes mezőkhöz egymástól független opciókészletet. (A könyv eredeti kiadásának tárgymutatóját kulcsszavakra a -df, oldalszámokra a -n opcióval rendezte egy hasonló rendezőprogram.)
5.12. Bonyolultabb deklarációk
A C nyelvet gyakran bírálják a deklarációinak szintaxisa miatt, különösen a függvényekhez tartozó mutatók használata esetén. A szintaxis megkísérli összeegyeztetni a deklarációt a gyakorlati alkalmazással, ami az egyszerűbb esetekben jól megoldható, viszont a bonyolultabb esetekben zavarokhoz vezethet. Ennek főleg az az oka, hogy egy deklaráció nem olvasható egyszerűen balról jobbra és túl sok a zárójel is. Az
int *f();
és
int (*pf)();
deklarációk közötti különbség jól mutatja a problémát. A * egy prefix operátor, ami alacsonyabb precedenciájú, mint a (), ezért zárójeleket kell alkalmazni a megfelelő végrehajtási sorrend érdekében. Bár a valóban bonyolult deklarációk csak ritkán fordulnak elő a gyakorlatban, fontos, hogy értelmezni tudjuk őket és ha szükséges, képesek legyünk létrehozni ilyen deklarációkat. Jó módszer a deklarációk kis lépésekben történő felépítésére a typedef parancs, amelyen majd a 6.7. pontban foglalkozunk. Egy másik lehetőség, amivel most fogunk megismerkedni, egy programpár, amelyek egyike az érvényes C nyelvű deklarációt szöveges leírássá alakítja, ill. a másik a szöveges leírásból C nyelvű deklarációt hoz létre. A programmal kapott szöveges leírás már balról jobbra olvasható.Az első, dcl nevű program a bonyolultabb, és ennek feladata a C-beli deklarációk szavakra fordítása úgy, ahogy ez az alábbi példákban* látható:
char **argv argv: pointer to pointer to char int (*daytab)[13] daytab: pointer to array[13] of int int *daytab[13] daytab: array[13] of pointer to int void *comp comp: function returning pointer to void void (*comp)() comp: pointer to function returning void char(*(*x())[])() x: function returning pointer to array[] of pointer to function returning char char(*(*x[3])())[5] x: array[3] of pointer to function returning pointer to array[5] of char
A dcl program az A. Függelék 8.5. pontjában részletesen leírt deklarátor által specifikált grammatikán alapszik. A deklarátor (rövidítve dcl) egyszerűsített alakja:
dcl: opcionális_*direkt-dcl direkt-dcl: név (dcl) direkt-dcl() direkt-dcl[opcionális_méret]
Szavakba foglalva, a dcl direkt-dcl, ha (esetleg) megelőzi egy *. Egy direkt-dcl egy név, vagy egy zárójelezett dcl, vagy egy direkt-dcl, amit zárójel követ, vagy egy direkt-dcl, amit szögletes zárójel és opcionális méretmegadás követ.Ez a grammatika a deklarációk elemzésére használható. Példaképpen nézzük a következő deklarátort:
(*pfa[])()
Ebben pfa-t, mint egy nevet azonosíthatjuk és így direkt-dcl típusú. Ekkor pfa[] szintén direkt-dcl. Ezután a *pfa[]-ról felismerjük, hogy dcl típusú, ezért (*pfa[]) direkt-dcl. Ekkor (*pfa[])() egy direkt-dcl és így a definíció szerint az egész kifejezés dcl típusú. Az elemzés menetét az alábbi elemzőfával szemléltethetjük (a direkt-dcl helyett a dir-dcl rövidítést használva):
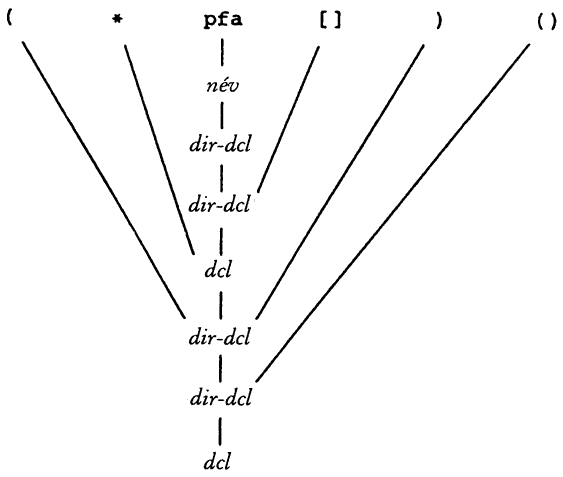
A dcl program legfontosabb része a dirdcl és dcl függvénypár, amelyek a vázlatosan ismertetett grammatika szerint elemzik a deklarációt. Mivel a grammatika rekurzívan van definiálva, ezért az egyes függvények is rekurzívan hívják egymást mindaddig, amíg fel nem ismerik a deklaráció egy darabját. Ennek megfelelően ez egy rekurzívan leszálló elemző program.
void dcl(void) { int ns; for (ns = 0; gettoken() == '*';) ns++; dirdcl(); while (ns-- > 0) strcat(out, " pointer to") ; } void dirdcl(void) { int type; if(tokentype == '(') { dcl(); if (tokentype != ')') printf("error: missing )\n"); } else if (tokentype == NAME) strcpy (name, token); else printf("error: expected name or (dcl)\n"); while((type=gettoken()) == PARENS || type == BRACKETS) if (type == PARENS) strcat(out, " function returning"); else { strcat(out, " array"); strcat(out, token); strcat(out, " of"); } }
Mivel a programot csak példának szántuk, nem igazán „bombabiztos”, a dcl programban van néhány jelentős megszorítás: csak az egyszerű adattípusokat (mint char vagy int) képes kezelni és a rosszul elhelyezett szóközök is megzavarhatják a működését. Mivel a programban nincs hibaállapot-helyreállítás, így az érvénytelen deklarációk is hibás működéshez vezetnek. Ezeknek a hibáknak a kijavítását a gyakorlott programozókra bízzuk.A program globális változói és a main eljárás:
#include <stdio.h> #include <string.h> #include <ctype.h> #define MAXTOKEN 100 enum { NAME, PARENS, BRACKETS }; void dcl(void); void dirdcl(void); int gettoken(void); int tokentype; char token[MAXTOKEN]; char name[MAXTOKEN]; char datatype[MAXTOKEN]; char out[1000]; main() { while (gettoken() != EOF) { strcpy(datatype, token); out[0] = '\0'; dcl(); if (tokentype != '\n') printf("syntax error\n"); printf("%s: %s %s\n", name, out, datatype); } return 0; }
A gettoken függvény átlépi a szóközöket és tabulátorokat, majd megkeresi a következő szintaktikai elemet (tokent) a bemeneti karaktersorozatban. Egy token lehet egy név, egy kerek zárójelpár, egy szögletes zárójelpár (amiben esetleg egy szám áll) vagy bármilyen egymagában álló karakter.
int gettoken(void) { int c, getch(void); void ungetch(int); char *p = token; while ((c = getch()) == ' ' || c == '\t') ; if (c == '(') { if ( (c = getch ()) == ')') { strcpy (token, "()"); return tokentype = PARENS; } else { ungetch(c); return tokentype = '('; } } else if (c == '[') { for (*p++ = c; (*p++ = getch()) != ']' ; ) ; *p = '\0'; return tokentype = BRACKETS; } else if (isalpha(c)) { for (*p++ = c; isalnum(c = getch ());) *p++ = c; *p = '\0'; ungetch(c); return tokentype = NAME; } else return tokentype = c; }
A getch és ungetch függvényeket a 4. fejezetben már ismertettük.A feladat megfordítása viszonylag egyszerű, főleg ha nem törődünk a feleslegesen generált zárójelekkel. Az undcl program az „x is a function returning a pointer to an array of pointers to functions returning char” (x char típusú adatokkal visszatérő függvények mutatóiból alkotott tömb mutatójával visszatérő függvény) alakú szóbeli leírásból, ami az
x () * [] * () char karaktersorozattal fejezhető ki, előállítja a
char (*(*x())[])() deklarációt. A rövidített bemeneti szintaxis lehetővé teszi, hogy újra a gettoken függvényt használjuk. Az undcl függvény ugyanazokat a külső változókat használja, mint a dcl.
main() { int type; char temp[MAXTOKEN]; while (gettoken() != EOF) { strcpy(out, token); while ((type = gettoken()) != '\n') if (type == PARENS || type == BRACKETS) strcat(out, token); else if (type =='*') { sprintf(temp, "(*%s)", out); strcpy(out, temp); } else if (type == NAME) { sprintf (temp, "%s %s", token, out); strcpy(out, temp); } else printf("invalid input at %s\n", token); printf ("%s\n", out); } return 0; }
A programban használt sprintf függvény a printf-hez hasonló könyvtári függvény, a printf-nek megfelelően formátumozza a kiírandó adatokat, de kiírás helyett az első argumentumában (aminek karaktersorozatnak kell lenni) tárolja. Bővebb leírása a 7.2. pontban, ill. a B. Függelékben található.
5.18. gyakorlat. Egészítse ki a dcl programot a bemeneti hibákat megszüntető hibahelyreállító eljárással!
5.19. gyakorlat. Módosítsa az undcl programot úgy, hogy ne írjon ki felesleges zárójeleket a deklarációkban!
5.20. gyakorlat. Bővítse ki a dcl programot úgy, hogy kezelni tudja a függvényargumentum típusú és const-hoz hasonló minősítőket tartalmazó deklarációkat is!
| 4. FEJEZET | Tartalom | 6. FEJEZET |